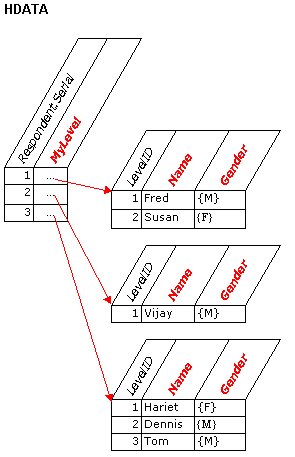
|
ID
|
Area
|
HouseType
|
Gender
|
Age
|
Vote
|
Transport
|
UseItOften
|
|---|---|---|---|---|---|---|---|
|
1
|
North
|
Flat
|
Male
|
30
|
Lib
|
Car
|
True
|
|
|
|
|
|
|
|
Bike
|
False
|
|
|
|
|
Fem
|
28
|
Dem
|
Bike
|
True
|
|
2
|
East
|
Farm
|
Male
|
65
|
Con
|
Car
|
False
|
|
|
|
|
|
|
|
Bike
|
True
|
|
|
|
|
|
|
|
Truck
|
False
|
|
3
|
South
|
Villa
|
Male
|
25
|
Lib
|
Car
|
True
|
|
|
|
|
|
|
|
Car
|
False
|
|
ID
|
Area
|
HouseType
|
Gender
|
Age
|
Vote
|
Transport
|
UseItOften
|
|---|---|---|---|---|---|---|---|
|
1
|
North
|
Flat
|
Male
|
30
|
Lib
|
Car
|
True
|
|
1
|
North
|
Flat
|
Male
|
30
|
Lib
|
Bike
|
False
|
|
1
|
North
|
Flat
|
Fem
|
28
|
Dem
|
Bike
|
True
|
|
2
|
East
|
Farm
|
Male
|
65
|
Con
|
Car
|
False
|
|
2
|
East
|
Farm
|
Male
|
65
|
Con
|
Bike
|
True
|
|
2
|
East
|
Farm
|
Male
|
65
|
Con
|
Truck
|
False
|
|
3
|
South
|
Villa
|
Male
|
25
|
Lib
|
Car
|
True
|
|
3
|
South
|
Villa
|
Male
|
25
|
Lib
|
Car
|
False
|
ID | Area | HouseType | Gender | Age | Vote | Transport | UseItOften |
|---|---|---|---|---|---|---|---|
1 | North | Flat | Person | ||||
Male | 30 | Lib | Vehicle | ||||
Car | True | ||||||
Bike | False | ||||||
Fem | 28 | Dem | Vehicle | ||||
Bike | True | ||||||
2 | East | Farm | Person | ||||
Male | 65 | Con | Vehicle | ||||
Car | False | ||||||
Bike | True | ||||||
Truck | False | ||||||
3 | South | Villa | Person | ||||
Male | 25 | Lib | Vehicle | ||||
Car | True | ||||||
Car | False |