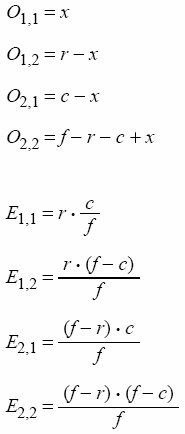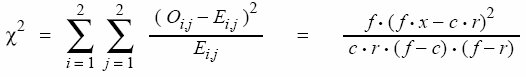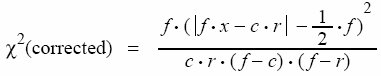|
Notation
|
Description
|
|---|---|
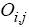 |
The observed values.
|
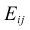 |
The expected values given the null hypothesis.
|
|
|
Total
|
Column
|
NOT column
|
|---|---|---|---|
|
Total
|
f
|
c
|
f-c
|
|
Row
|
r
|
x
|
r-x
|
|
NOT row
|
f-r
|
c-x
|
f-r-c+x
|
|
Notation
|
Description
|
|---|---|
|
The observed values.
|
|
The expected values given the null hypothesis.
|