Loops, grids, and levels
Market research questionnaires often contain individual questions and sets of questions that are asked more than once. For example, questionnaires often contain grid questions that ask respondents to choose a rating on a predefined scale for a number of products in a list, and sets of questions that respondents are asked to answer for each product in a list of products or for each person in a household.
The number of times the question or set of questions is to be asked can be controlled in these ways:
▪By the categories in a category list. For example, “For each brand in the following list, please answer the following...”
▪By a numeric expression that has a known upper limit. For example, “For each of the first three journeys you described earlier, please answer the following...”
▪By a numeric expression that has an unknown upper limit. For example, “For each drink you consumed last week, please answer the following...”
Each of these constructions is a loop that defines the question or set of questions and the number of times they are to be asked (or, in more technical terms, the number of times the loop is to be iterated). Whether the questions in the loop are asked simultaneously as a grid or sequentially (one after the other) is not relevant to how the data is stored.
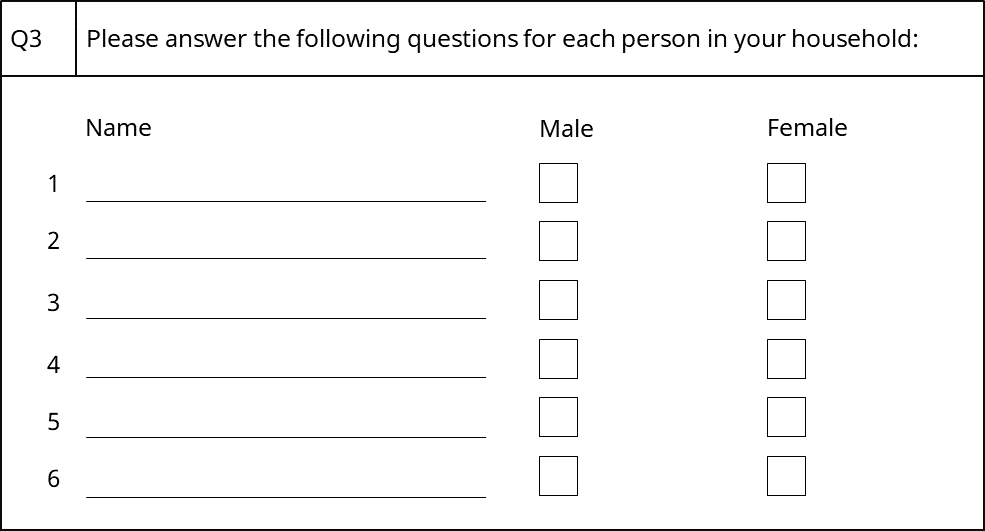
To understand how it works, consider the following loop, which is presented here in a grid-like format:
Numeric loop
This loop contains two questions, Name and Gender, which are asked up to 6 times. This means that the loop has 6 iterations.
When the response data is presented in a non-hierarchical form, it is “flattened” and a separate column stores the responses to each question in each possible iteration. In this example, there would be 12 columns (2 * 6). For example, if the loop is called MyLoop, the following columns would store the responses:
MyLoop[1].Name
MyLoop[2].Name
MyLoop[3].Name
MyLoop[4].Name
MyLoop[5].Name
MyLoop[6].Name
MyLoop[1].Gender
MyLoop[2].Gender
MyLoop[3].Gender
MyLoop[4].Gender
MyLoop[5].Gender
MyLoop[6].Gender
In the metadata variable instances are used to map the questions to the case data columns and the full names of the variable instances correspond to the names of the columns. The full names are constructed from the names of the loop and the questions inside the loop. [ ] (brackets) indicate an iteration, and . (period) indicates a parent/child relationship.
This method of representing hierarchical data is simple and effective. However, it has some disadvantages, the most obvious one being that the number of columns is fixed. In our household example, this means that storage space is reserved for the responses of six individuals in each household even though many households have fewer people. Conversely, responses cannot be stored for any additional people in large households. Another disadvantage is that performing summary calculations on the data can be difficult.
Representing the case data hierarchically can be more flexible and provides advantages during analysis. The loop is then considered a level and the responses to the questions in the loop are stored in a separate hierarchical table named after the loop. The hierarchical table would contain a column for each of the questions in the loop, and store the responses to each iteration in a separate row. In the metadata, the variables nested inside the loop correspond to the columns in the lower-level virtual tables. The full names of the variables in this example would be:
MyLevel[..].Name
MyLevel[..].Gender
.. (two periods) are used instead of an iteration number, to indicate all iterations.
Whether the UNICOM Intelligence Data Model represents the data hierarchically or flattened depends on the CDSC you are using (and therefore the format of the underlying data) and how the data was defined. In some data formats, loops can be represented both hierarchically and flattened. These loops are known as expanded loops. However, loops in which the maximum number of iterations is unknown cannot be expanded. These loops are sometimes referred to as unbounded loops.
A grid is a special case of a loop, in which the iterations are controlled by a category list and the iterations are presented simultaneously when the grid question is asked. In addition, a grid can generally be represented in a flattened form, although if the data format supports a hierarchical view of the data, it will be represented in a hierarchical form as well. In the Museum survey there is a grid question that asks respondents to rate the galleries in the museum:
Rating grid
In this grid, the list of galleries is the controlling category list, the grid itself is called rating and the categorical question inside the grid is called column. The full names of the individual variable instances that correspond to the columns that store the responses in a flattened form are:
rating[{Dinosaurs}].Column
rating[{Conservation}].Column
rating[{Fish_and_reptiles}].Column
rating[{Fossils}].Column
rating[{Birds}].Column
rating[{Insects}].Column
rating[{Whales}].Column
rating[{Mammals}].Column
rating[{Minerals}].Column
rating[{Ecology}].Column
rating[{Botany}].Column
rating[{Origin_of_species}].Column
rating[{Human_biology}].Column
rating[{Evolution}].Column
rating[{Wildlife_in_danger}].Column
rating[{Other}].Column
These are sometimes referred to as grid slices.
When the question or questions inside the grid are numeric rather than categorical, the grid is sometimes referred to as a numeric grid question. For example, in the Short Drinks sample data, there is a numeric grid question that asks respondents to enter the number of drinks of various types they consumed each day of the previous week:
In this example, the drinks are the iterations (called subquestions in some end-user documentation) and the days of the week are numeric questions inside the loop.
See also