In a multi-database system, the usage of databases can vary a lot. Therefore you must consider the way databases in your system will be used when physically implementing and tuning them.
Following are the guidelines for using schemas and catalogs. See the section that applies to your advanced replication architecture.
Guidelines for a two-tier topology
A two-tier data redundancy model has one master database and multiple replica databases. Both master and replica databases can have different schemas using the default schema name which is the user id of the database owner. In this case, no schema is explicitly defined; instead the server automatically assigns one with the user id. It is recommended that you use identical schema names for the master and replica databases. Although you can use different schema names, be aware that different schema names in master and replicas may complicate the application programming.
To use schemas, a schema name must be created before creating the database objects that will be associated with the schema. To create a schema use the CREATE SCHEMA command. See the solidDB® SQL Guide for details.
Guidelines for multi-tier topology
A multi-tier topology contains three or more tiers in the hierarchy of synchronized databases. The top tier of the topology is the master database for the overall system. The mid-tier databases of the topology have a dual role of both master and replica databases. The lowest tier contains only replicas.
A multi-tier topology is especially useful in systems that have a wide geographic distribution and a potentially large number of replica databases that also have local data (i.e. data that does not require synchronization with the top-tier master). The data in this type of system is typically partitioned to limit data access to specific replicas. For example, a network management system that contains a database to manage configuration and event information for a large managed network meets the criteria for a multi-tier topology.
Guidelines for multi-master topology
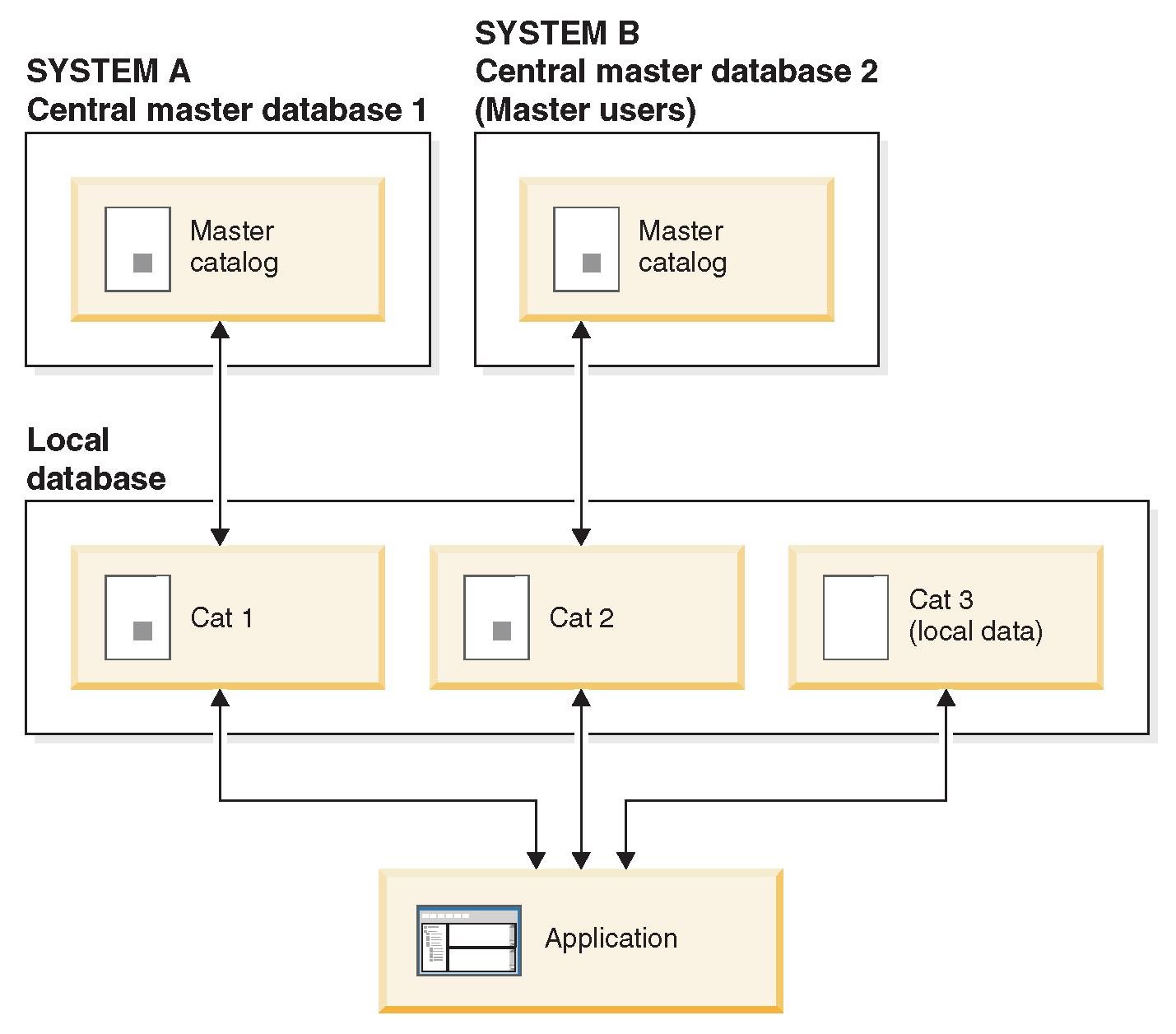
solidDB®’s physical database file may contain more than one logical database. Each logical database is a complete, independent group of database objects, such as tables, indexes, procedures, triggers, and so on. Each logical database is implemented as a database catalog. Each of these catalogs can act as an independent master or replica database. This makes it possible, for example, to create two or more independent replica databases into one physical local database. It is also possible to have one or more catalogs in this same local database that each contain a master database.
Multi-master topologies are useful in environments where a solidDB® database is used by multiple applications. For example, a local database may contain a replica of two masters: one for a configuration management application and another one for a usage-monitoring application. Note that you can combine multi-tier and multi-master topologies.
Creating Catalogs
The following are guidelines for designing and implementing multiple catalogs used for synchronization:
▪When creating a database, solidDB® creates a default catalog for the database.
▪Besides the default catalog, a single solidDB® database can contain any practical number of catalogs.
▪If you do not explicitly CREATE and SET any catalogs, then you will use the default catalog for the database.
▪Each catalog of a database can be either a master, replica, or both.
▪Each catalog can contain multiple schemas. Transactions can access database objects in any catalog.
▪A catalog can contain local tables as well as tables that are synchronized with a master. A single transaction may use a combination of local tables and master tables.
▪The physical database has a set of defined local users that have access to the local data management functions. For accessing the data synchronization functions, each catalog has one or more master users that have been downloaded as part of a replica registration.
To create and set catalogs for masters and replicas, use the CREATE CATALOG and SET CATALOG commands. See the CREATE CATALOG and SET CATALOG commands in the solidDB® SQL Guide for details on creating and setting catalogs.
On Master:
CREATE CATALOG INVENTORY; SET CATALOG INVENTORY; COMMIT WORK;
On Replica:
CREATE CATALOG INVENTORY SET CATALOG INVENTORY COMMIT WORK;
Notes
▪Acatalognamedoesnotneedtobethesameinamasterandreplica.wantto use (if you do not specify a fully qualified name).
▪Whenactuallyusingthecatalogsaftertheyarecreated,youmayspecifythem by using fully-qualified table names (including the catalog name), or you may use the SET CATALOG command to specify which catalog you want to use (if you do not specify a fully qualified name).
Using Schemas within Catalogs
To logically partition a database, you create a catalog(s) first before you create a schema. After you create the catalog and schema, you then create the database
objects that will be associated with the schema. If you create the database objects without a specified schema, the schema becomes your user id.
You may use multiple schemas within catalogs (although a single schema may be sufficient). If you have multiple schemas, you may specify them either by including the schema as part of the table name, or you may use the SET SCHEMA command to specify which schema you want to use.
If you do not explicitly CREATE and SET any schema name, then you will use the default schema name, which is your user id.
Note With catalogs, there is one default for the entire database, but with schemas, there is one default for each user — there is NOT one default for the entire database.
See the CREATE SCHEMA and SET CATALOG commands in the SQL Guide for details on creating and setting schemas.
Set up data for synchronization
This section applies to both two-tier, and multi-tier, multi-level architectures. It assumes that you have created your catalogs and schema names (if required).
The following are guidelines for designing and implementing the schema and using the CREATE TABLE command to create the master database and replica database tables.
You define tables that are required for synchronization and will be used in a publication. A publication is a set of data to be downloaded from the master database to a replica database. When creating your schema you need to define:
▪Tables of the master database
▪Tables of the replica database
▪Replica databases can contain all tables of the master database or a subset of them.
▪Replica databases can also contain tables that are for local use only.
▪Replica tables can contain a subset of columns from the master table.
▪The name of the replica table can be different from the master table. When publications are created using the CREATE PUBLICATION command, a master table name can be associated with a replica table that has a different name. The publication definition takes care of the mapping between the master and replica tables.
Keep in mind the following when creating tables:
▪All tables in the schema must have a user-defined primary key. The primary keys in master and replica tables must be identical and uniqueness must be guaranteed globally. More columns in a replica’s primary key will lead to conflicts in propagating transactions to the master database. More columns in a master’s primary key will similarly lead to conflict when refreshing data to a replica.
▪Apply the ALTER TABLE SET SYNCHISTORY command to enable incremental publications on the master and replica tables. Otherwise the master sends the replica full publications (which use more resources) rather than incremental publications.
By setting the SYNCHISTORY property for each table of the publication in both the master and the replica databases, you allow the creation of a shadow history table that keeps track of data updates for incremental publication. For details on the ALTER TABLE syntax, see Creating incremental publications.