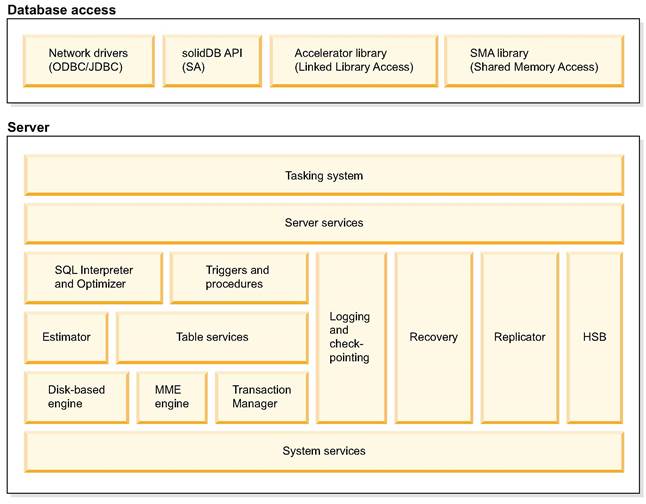
The solidDB® server processes the data requests submitted through solidDB® SQL. The server stores data and retrieves it from the database.
Tasking system
The tasking system is a framework to abstract threads to a concept task. Tasking system implements concurrent execution of the tasks also in single threaded systems.
Server services
The server services component contains services and utilities to use components on the lower levels.
SQL interpreter and optimizer
The SQL interpreter and optimizer is responsible of SQL-clause parsing and optimization. The solidDB® server uses SQL syntax that is based on the ANSI X3H2 and IEC/ISO 9075 SQL standards. The SQL-89 Level 2 standard is fully supported and SQL-92 Entry Level. Many features of full SQL-92, SQL-99, and SQL-2003 standards are also supported.
solidDB® contains a cost-based optimizer, which ensures that even complex queries can be run efficiently. The optimizer automatically maintains information about table sizes, the number of rows in tables, the available indexes, and the statistical distribution of the index values.
Triggers and procedures
The triggers and procedures component contains a mechanism for parsing and executing SQL-based stored triggers and procedures:
▪A trigger activates stored procedure code, which the solidDB® server automatically executes when a user attempts to change the data in a table.
▪Stored procedures are simple programs, or procedures, that are executed in the solidDB® server. You can create procedures that contain several SQL statements or whole transactions, and execute them with a single call statement. In addition to SQL statements, 3GL type control structures can be used enabling procedural control. In this way complex, data-bound transactions can be run on the server itself, thus reducing network traffic.
Logging and checkpointing
The logging and checkpointing component is responsible for maintaining persistency of transactions by write-ahead logging, consistency, and recoverability of the database by checkpointing. Various durability options are available. Reading the transaction log file as it is being written by the server is possible and is done with a special SQL-based interface called Logreader API.
Recovery
The recovery component is responsible for recovery from transaction log and database checkpoints.
Replicator
The replicator component provides support for the advanced replication feature. The advanced replication feature is used for asynchronous, pull-based replication between a master database and replica databases. A master database contains the master copy of the data. One or more replica databases contain full or partial copies of the data. A replica database, like any other database, can contain multiple tables. Some of those tables can contain only replicated data (copied from the master), some can contain local-only data (not copied from the master), and some can contain a mix of replicated data and local-only data. Replicas can submit updates to the master server, which then verifies the updates according to rules set by the application programmers. The verified data is then published and made available to all replicas.
HotStandby
The HotStandby (HSB) component enables a secondary server (a hot standby server) to run in parallel with the primary server and keep an up-to-date copy of the data in the primary server.
Estimator
The estimator component provides cost-based estimates for single table access based on projections and constraints. It executes a low-level execution plan generation by using index selection and index range calculations.
Table services
The table services module contains interfaces for single-table access, data type support, transaction management interface, and table and index caches.
Main-memory engine (MME)
The main-memory engine component handles the storage of in-memory tables (M‑tables) and indexes.
Transaction manager
The transaction manager component contains commit and rollback implementation and concurrency conflict checking and resolution.
System services
The system services component contains operating system abstraction layer, memory management, thread management, mutexing, and file I/O services.
SQL processing
The solidDB® server uses a cost-based optimizer that ensures that SQL statements are executed efficiently.
Optimizer
The solidDB® SQL optimizer is a cost-based optimizer. It uses the same techniques as a rules-based optimizer, relying on a preprogrammed set of rules to determine the shortest path to the results. For example, the optimizer considers whether an index exists, if the index is unique, and if the index is over single or composite table columns. However, unlike a rule-based optimizer, the cost-based optimizer can adapt to the actual contents of the database, for example, the number of rows and the value distribution of individual columns.
The server maintains the statistical information about the actual data automatically, ensuring optimal performance. Even when the amount and content of data changes, the optimizer can still determine the most effective route to the data.
Query processing
Queries are processed in small steps to ensure that one time-consuming operation does not block other application requests. A query is processed in a sequence that contains the following phases:
▪Syntax analysis
▪Creating the execution graph
▪Processing the execution graph
Syntax analysis
An SQL query is analyzed and the server produces either a parse tree for the syntax or a syntax error. When a statement is parsed, the information necessary for its execution is loaded into the statement cache. A statement can be executed repeatedly without re-optimization, on condition that its execution information remains in the statement cache.
Creating the execution graph
The execution graph, which contains the following features, is created from the query parse tree.
▪Complex statements are written to a uniform and more simple form.
▪If better performance can be realized, OR criteria are converted to UNION clauses.
▪Intelligent join constraint transfer is performed to produce intermediate join results that reduce the join process execution time.
You can use the EXPLAIN PLAN FOR statement to show the execution plan that the SQL optimizer selected for the SQL statement.
Processing the execution graph
The execution graph is processed in three consecutive phases:
▪Type-evaluation phase
The column data types of the result set are derived from the underlying table and view definitions.
▪ Estimate-evaluation phase
The cost of retrieving first rows and also entire result sets is evaluated, and an appropriate search strategy is dynamically selected based on the parameter values that are bound to the statement.
The SQL Optimizer bases cost estimates on automatically maintained information about key value distribution, table sizes, and other dynamic statistical data. Manual updates to the index histograms or any other estimation information are not required.
▪Row-retrieval phase
The result rows of the query are retrieved and returned to the client application.
Optimizer hints
Optimizer hints are an extension to solidDB® SQL. They are directives that are specified through embedded pseudo comments within query statements. The optimizer detects these directives or hints and bases its query execution plan accordingly. Optimizer hints allow applications to be optimized under various conditions to the data, query type, and the database. They not only provide solutions to performance problems occasionally encountered with queries, but shift control of response times from the system to the user.
solidDB® network services
solidDB® network services are based on the remote procedure call (RPC) paradigm, which makes the communication interface simple to use. When a client sends a request to the server, it resembles calling a local function. The network services invisibly route the request and its parameters to the server, where the actual service function is called by the RPC server. When the service function completes, the return parameters are sent back to the calling application.
In a distributed system, several applications can request a server to run multiple operations concurrently. For maximum parallelism, solidDB® network services use the operating system threads when available to offer a seamless multiuser support. On single-threaded operating systems, the network services extensively use asynchronous operations for the best possible performance.
Communication session layer
The solidDB® communication protocol DLLs (or static libraries) offer a standard internal interface to each protocol. The lowest part of the communication session layer works as a wrapper that takes care of choosing the correct protocol DLL or library that relates with the address information. After this point, the actual protocol information of the session is hidden. solidDB® can listen to several protocols simultaneously.
Multithread processing
The solidDB® multithread architecture provides an efficient way of sharing the processor within an application. A thread is a dispatchable piece of code that merely owns a stack, registers (while the thread is executing), and its priority. It shares everything else with all other active threads in a process. Creating a thread requires much less system overhead than creating a process, which consists of code, data, and other resources such as open files and open queues.
Threads are loaded into memory as part of the calling program; no disk access is therefore necessary when a thread is invoked. Threads can communicate using global variables, events, and semaphores.
If the operating system supports symmetric multithreading between different processors, solidDB® automatically takes advantage of the multiple processors.
Types of threads
The solidDB® threading system consists of general-purpose threads and dedicated threads.
General-purpose threads
General-purpose threads execute tasks from the server’s tasking system. They execute such tasks as serving user requests, making backups, executing timed commands, merging indexes, and making checkpoints (storing consistent data to disk).
General-purpose threads take a task from the tasking system, execute the task step to completion and switch to another task from the tasking system. The tasking system works in a round-robin fashion, distributing the client operations evenly between different threads.
The number of general-purpose threads can be set in the solid.ini configuration file.
Dedicated threads
Dedicated threads are dedicated to a specific operation. The following dedicated threads can exist in the server:
▪I/O manager thread
This thread is used for intelligent disk I/O optimization and load balancing. All I/O requests go through the I/O manager, which determines whether to pass each I/O request to the cache or to schedule it among other I/O requests. I/O requests are ordered by their logical file address. The ordering optimizes the file I/O since the file addresses accessed on the disk are in close range, reducing the disk read head movement.
▪Communication read threads
Applications always connect to a listener session that is running in the selector thread. After the connection is established, a dedicated read thread can be created for each client.
▪One communication select thread per protocol (known as the selector thread)
There is usually one communication selector thread per protocol. Each running selector thread writes incoming requests into a common message queue.
▪Communication server thread (also known as the RPC server main thread)
This thread reads requests from the common message queue and serves applications by calling the requested service functions.