The internal part of the server that takes care of storing D-tables is called the disk-based engine (DBE). The main data structure that is used to store D-tables is a B-tree variation called B+tree. The server uses two structures; the main storage tree holds permanent data, and a differential index tree called Bonsai Tree stores new data temporarily until it is ready to be moved to the main storage tree.
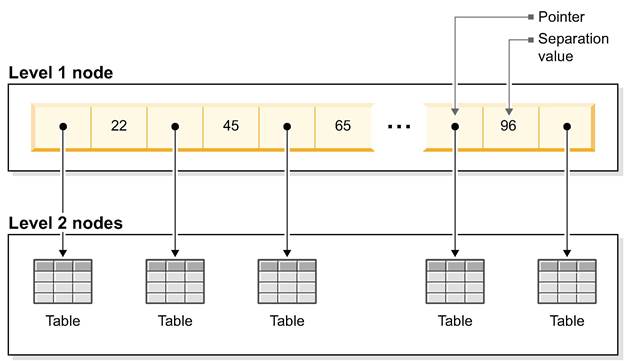
A basic B+tree with two node levels is illustrated in the following figure.
Each node has a large set of value-pointer pairs. They normally fill a database page that is a unit of data buffering. The page sizes vary from 4 to 32 KB. Compared to VTrie, the page size makes the nodes much larger, resulting in a wide, or bushy tree. The key value is compared against the separation values in the node and, if the key value falls between two separation values, the corresponding pointer is followed to a similar node on the next level. Thanks to a large node size, the number of disk accesses is minimized, and that make B-tree fit for D-tables.
The server uses two incarnations of a B-tree: the main storage tree holds permanent data, and a differential index tree called Bonsai Tree stores new data temporarily until it is ready to be moved to the main storage tree. In both B-tree structures, two space optimization methods are used. First, only the information that differentiates the key value from the previous key value is saved. The key values are said to be prefix-compressed. Second, in the higher levels of the index tree, the key value borders are truncated from the end; that is, they are suffix-compressed.
Main storage tree
The main storage tree contains all the data in the server, including tables and indexes. Internally, the server stores all data in indexes; there are no separate table stores. Each index contains either complete primary keys (all the data in a row) or secondary keys (what SQL refers to as indexes, which are the column values that are part of the SQL index). There is no separate storage method for data rows, except for binary large objects (BLOB) and other long column values.
All the indexes are stored in a single tree, which is the main storage tree. Within that tree, indexes are separated from each other by a system-defined index identification that is inserted in front of every key value. This mechanism divides the index tree into several logical index subtrees where the key values of one index are clustered close to each other.
Bonsai Tree multiversioning and concurrency control
The Bonsai Tree is a small active index (data storage tree) that efficiently stores new data (deletes, inserts, updates) in central memory, maintaining multiversion information. Multiple versions of a row (old and new) can coexist in the Bonsai Tree. Both the old and new data are used for concurrency control and for ensuring consistent read levels for all transactions without any locking overhead. With the Bonsai Tree, the effort that is needed for concurrency control is reduced.
When a transaction is started, it is given a sequential Transaction Start Number (TSN). The TSN is used as the “read level” of the transaction; all key values that are inserted later into the database from other connections are not visible to searches within the current transaction. This approach offers consistent index read levels that appear as though the read operation was performed at the time the transaction was started. This way ensures that read operations are presented with a consistent view of the data without the need for locks, which have higher overhead.
Old versions of rows (and the newer version or versions of those same rows) are kept in the Bonsai Tree for as long as transactions need to see those old versions. After the completion of all transactions that reference the old versions, the old versions of the data are discarded from the Bonsai Tree, and new committed data is moved from the Bonsai Tree to the main storage tree. The presorted key values are merged as a background operation concurrently with normal database operations. This way offers significant I/O optimization and load balancing. During the merge, the deleted key values are physically removed.