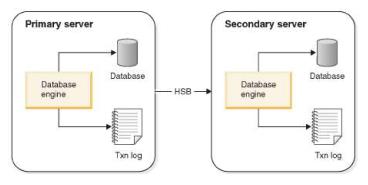
In the basic HotStandby server scheme, there are two database servers, the Primary and the Secondary server. Both servers have their own disk drives on which they stores the database, and each of which have their own transaction logs (Txn Log).
The diagram below illustrates the basic HotStandby server scheme. The Primary writes to its transaction log and forwards it to the Secondary so that the Secondary can make the same changes to its copy of the database. The transaction log on the Secondary is not actively involved in HSB, but it is maintained so that the Secondary can recover data that was committed but not yet written to the main data tables.
Heartbeat
Internally, solidDB® HSB uses a technique, which is referred to as heartbeat, to monitor the connection between servers.
Sequences of keepalive messages are sent between active and standby servers. Both servers continuously send the unidirectional “I am here” messages to the other server. The messages are sent on a fixed time interval. A message from the other server is expected to arrive within a predefined time window. In solidDB®, the heartbeat technique is called ping.
Important: In solidDB® the heartbeat technique is called ping, although there are no ping requests sent. The heartbeat technique is different from the Ping protocol used in Internet Protocol networks.
The transaction log and HotStandby
HotStandby uses the Primary server transaction log, which contains a copy of the transactions that are committed on the server. In a non-HotStandby server, this transaction log is used to recover data if the server shuts down abnormally.
In a HotStandby Primary server, the log data is also sent to the Secondary server so that the Secondary knows what data to update. The Secondary database runs a continuous roll-forward process that receives the log data and keeps the copy of the data on the Secondary synchronized with the Primary.
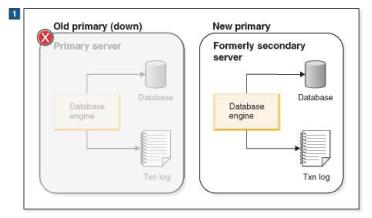
If the Primary server fails, a watchdog application tells the secondary to become the Primary. When the new Primary is in operation, the clients can connect to it and continue working. Clients continue to see all data that was committed before the Primary went down. (Clients must restart any transactions that were started but not finished when the original Primary server went down.)
A special type of client connectivity called Transparent Connectivity (TC) is available for clients in the HSB environment that calls for handling of failovers and switchovers. For more information, see Using HotStandby with applications.
If the Secondary server fails, the Primary can continue to operate. It continues writing data to the transaction log and keeps that transaction log until the Primary and Secondary are reconnected to each other and the Primary has sent the log to the Secondary. The exact length of time that the Primary keeps the log depends upon the settings of the solid.ini configuration parameters General.CheckpointDeleteLog and General.BackupDeleteLog.
1 If General.CheckpointDeleteLog=Y, the Primary keeps all transaction logs since the time that the Secondary went down or since the most recent checkpoint, whichever is less recent.
2 If General.CheckpointDeleteLog=N and General.BackupDeleteLog=Y, the Primary keeps all transaction logs since the time that the Secondary went down or since the most recent backup, whichever is less recent.
3 If General.CheckpointDeleteLog=N and General.BackupDeleteLog=N, the server keeps the logs indefinitely.
When the failed database server becomes available again, it can be configured to become the new Secondary database server (the server that did not fail is already acting as the current Primary).
If the Primary server is the server that fails, then the servers will reverse their responsibilities, with the original Secondary taking over as the Primary, and the original Primary coming back into the system as the new Secondary after it is repaired. These reversals can happen each time there is a failure. The fact that either server can be the Primary allows the system to survive multiple failures over time, and continue operating indefinitely.
Note If the Primary server is unable to contact the Secondary server for a long time, the transaction log can fill all the available disk space. You can avoid running out of disk space because of large log files by applying appropriate configuration parameter settings. For more information, see Running out of space for transaction logs.
You can use HSB to reduce downtime during hardware and software upgrades. You can leave one server to run as Primary while you upgrade the other.
HotStandby can also be used to help choose a customized balance of speed and safety. The HSB parameters HotStandby.SafenessLevel and HotStandby.2SafeAckPolicy control the way the Secondary server acknowledges the transactions. Together with the logging-related Logging.DurabilityLevel parameter, these parameters let you specify a combination of speed and safety. Some parameter settings can increase performance over non-HSB servers. (For more information, see the discussion of durability level and safeness parameters in Performance tuning.
You can also configure the safeness level to change dynamically in relation to the durability level by using the HotStandby.SafenessLevel=auto setting.
Failover
In a failover, the secondary is switched to be the new primary.
There are several reasons for switching the secondary to new primary:
1 The primary fails-
2 You want to administer the primary.
3 You must choose a primary when there is no existing primary on the system.
The secondary is switched to be the new primary by issuing the following command on the Secondary server:
ADMIN COMMAND 'hotstandby set primary alone';
In the case of a failover, the new Primary contains the up-to-date committed data from the old Primary database. Everything that was committed in the Primary database, can be found from the Secondary database. If Transparent Connectivity (TC) is used, connections are not lost on the failover. However, the ongoing transactions are aborted and must be re-executed. For more information, see Failure transparency in Transparent Connectivity. The new Primary can operate alone and continue to write transactions and data to its database and transaction log.
▪The server that was originally the Secondary becomes the new Primary after the old Primary server fails.
Server Catchup
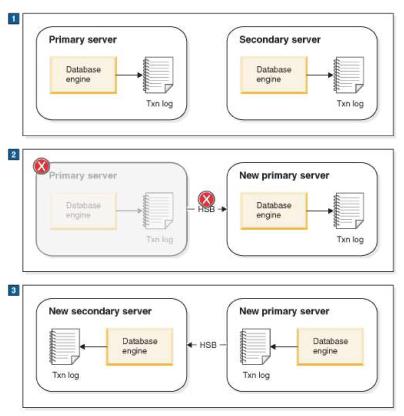
When the old Primary is back online, assuming that there is an existing Primary, it becomes the new Secondary. At this stage, the information in the new Secondary lags behind that of the new Primary as new transactions are committed to the new Primary database. To bring the new Secondary up to date, the transaction log data of the new Primary is sent to the new Secondary automatically after the servers are connected. All pending changes are written from the transaction log to the new Secondary so that the Secondary can keep in sync with the Primary. Server catchup is illustrated below.
1 Normal operation: Primary server sends data to Secondary server.
2 When Primary server fails, Secondary server takes over as the new Primary. New Primary server saves transaction information in its transaction log so that it can send the data to the new Secondary server later.
3 After the old Primary server is brought up as the new Secondary server, the information in the transaction log of the new Primary is sent to the new Secondary so that it can catch up.