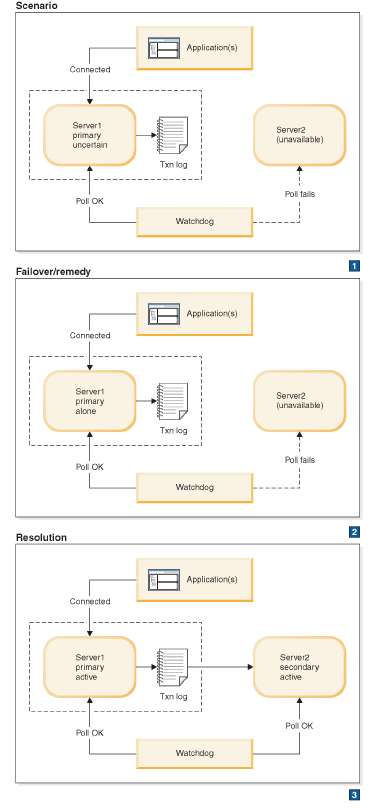
All connections to the Secondary server are broken. This may be caused either by a failure in the Secondary, or by a failure in the network that makes it impossible for either the Primary or the Watchdog to communicate with the Secondary server. In this section, the Secondary is referred to as failing, but in fact the problem may be with either the Secondary or the network.
Remedy
The standard remedy is to switch the Primary server to the PRIMARY ALONE state. After the Secondary is up again, synchronize it with the Primary.
Upon finding a problem with the connection to the Secondary server, the Primary server:
1 Suspends any open transactions, neither committing them nor rolling them back (the Primary does not send an error message — or a “success” message — to the client); and
2 Automatically switches its own state from PRIMARY ACTIVE to PRIMARY UNCERTAIN.
Typically, after making sure that the secondary server is unavailable, the watchdog will switch the Primary from PRIMARY UNCERTAIN to PRIMARY ALONE. After the Primary is switched to PRIMARY ALONE state, it can continue accepting transactions and saving them to send to the Secondary. Later, when the Secondary is brought back up, the Secondary can be sent the transaction log so that it can “catch up” to the Primary.
The Primary commits the open transactions after the Primary is set to PRIMARY ALONE state. To avoid the possibility that the Primary will commit the transactions when the Secondary has not, the transactions are kept in the transaction log, as though they had never been sent to the Secondary. When the Secondary is brought back up and starts catching up, the Primary sends that transaction log, and the Secondary checks each of the transactions. If any of the transactions are duplicates (that is, if the Secondary already committed that transaction before the Secondary failed), then the duplicate transactions are not re-executed on the Secondary.
The watchdog or system administrator must be careful in choosing whether to bring the Primary to PRIMARY ALONE state, or choose an alternative action. If the watchdog or system administrator chooses a different action than switching the Primary to PRIMARY ALONE state, she must take into account that the Secondary and Primary may not have the same data i.e. they may not both have rolled back the transaction. It is possible that the failed Secondary actually committed the data and crashed after committing the data but before sending the confirmation to the Primary, while the Primary never committed. In this situation, the secondary may actually be “ahead” of the Primary rather than behind it.
As always, the watchdog or administrator also must be careful not to allow both servers to go into PRIMARY ALONE state at the same time.
The diagram below is divided into three frames. The first frame shows the scenario, which is that the Primary and watchdog have lost contact with the Secondary. The next frame shows how to respond to keep your system working until the problem can be completely solved. The third frame shows the final state after the problem has been solved — that is, after the broken server has been fixed, or after communications have been restored.
▪Watchdog instructs Server 1:
HSB SET PRIMARY ALONE HSB SET STANDALONE
▪After Server 2 is brought back up, Watchdog instructs Server 1:
HSB NETCOPY HSB CONNECT
▪If the transaction log fills up, you may have to switch the PRIMARY ALONE server to STANDALONE. In that case, you will also need to execute HSB NETCOPY before you reconnect the servers. If the transaction log does not fill up, then you must skip the NETCOPY command.
Symptoms
The watchdog poll fails at the Secondary. The state of the primary server is either PRIMARY ALONE or PRIMARY UNCERTAIN.
How to recover when the secondary is down
About this task
To allow the Primary server to continue to receive transactions, operating independently of the Secondary server, do the following:
Procedure
1 If the Primary server is in the PRIMARY UNCERTAIN state, then set the Primary server to PRIMARY ALONE using the command:
ADMIN COMMAND 'hotstandby set primary alone';
2 After the Secondary server has been repaired and restarted and/or the Secondary’s network connections have been reestablished, check the state of the Primary server using the command:
ADMIN COMMAND 'hotstandby state';
3 If the state of the Primary server is PRIMARY ALONE, then reconnect the Primary to the Secondary using the command:
ADMIN COMMAND 'hotstandby connect';
4 If the state of the Primary server has earlier been changed to STANDALONE, then:
a Copy the database from the new Primary to the Secondary using the command: