2: Viewing the loops in the Household sample
The Household sample is an example hierarchical data set. It represents the data collected using this survey:
▪Household questions. Respondents are first asked a number of questions about their household as a whole, such as the address, age of the building, and number of rooms.
▪Person questions. Respondents are then asked a number of questions about each person in the household, such as the person's name, age, gender, and occupation, and a grid question that asks the number of days he or she watches various TV channels.
▪Overseas trip questions. Respondents are also asked a number of questions about each overseas trip that each person in their household has taken in the previous year (if any), such as the purpose of the trip, number of days he or she was away from home, and countries that were visited.
▪Vehicle questions. Finally, respondents are asked a number of questions about each vehicle that belongs to their household, such as the vehicle's type, color, and annual mileage, and a grid question that asks the respondent to rate the vehicle's features.
Loops called person, trip, and vehicle are used to ask the person, overseas trip, and vehicle questions, respectively. The loops are iterated (and therefore the questions are asked) as many times as necessary. For example, in a household of three people, the person loop will be iterated three times, whereas in a single-person household it will be iterated once. In a household that has no cars, bikes, or other vehicles, the vehicle questions will not be asked at all and the vehicle loop will have no iterations.
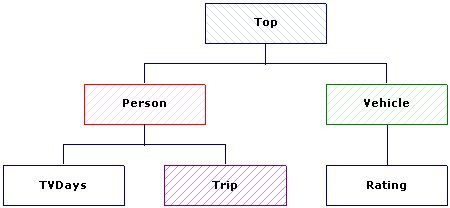
Each of these loops corresponds to an Array object in the metadata and a child table (called a level) in the hierarchical representation of the case data. In the Quanvert sample database, all three loops are unbounded loops (which means that the maximum number of iterations is unknown) and so they cannot be represented in the flat VDATA virtual table because flattening of the data is possible only if the maximum number of iterations is unknown. However, in the UNICOM Intelligence Data File version of the Household data set, the person loop has been changed to an expanded loop in order to provide additional examples of table scripting features.
The structure of the tables in the case data corresponds to the structure of the loops in the metadata. This means that because the trip loop is nested within the person loop, the trip table is a child of the person table. The two grids are also represented in the case data by hierarchical tables, each nested within its parent table. The following diagram shows the structure of the tables.
The UNICOM Intelligence Data File version of the Household sample data set consists of a metadata file (household.mdd) and a case data file (household.ddf).
1 Connect to the Household sample data set in DM Query: From the DM Query File menu, choose New Connection.
This opens the Connection tab in the Data Link Properties dialog box.
2 From the Metadata Type list, select UNICOM Intelligence Metadata Document.
3 Enter the Metadata Location: Click Browse, navigate to the folder in which the household.mdd file was installed, and then select it. By default, it is in:
[INSTALL_FOLDER]\IBM\SPSS\DataCollection\7\DDL\Data\Data Collection File\
4 From the Case Data Type list, select UNICOM Intelligence Data File (read-write).
5 Enter the Case Data Location: Click Browse, navigate to the folder in which the household.ddf was installed, and then select it. By default, it is in:
[INSTALL_FOLDER]\IBM\SPSS\DataCollection\7\DDL\Data\Data Collection File\
6 Leave the Case Data Project text box blank.
7 Click the Advanced tab, and from the "Reading categorical data" list, select Return category names. Click OK.
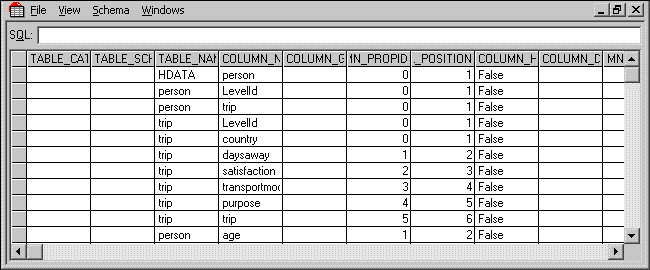
8 Look at the schema (by choosing Columns from the Schema menu in DM Query.)
The HDATA table has columns called person and vehicle. These store pointers to the person and vehicle tables, respectively. Similarly, the person table has columns called trip and tvdays, which store pointers to the trip and tvdays tables, respectively. Each of the tables nested under HDATA starts with a column called LevelId. For a grid or a categorical loop, this stores the name of the category that controls the iteration. For a numeric loop, this stores the iteration number.
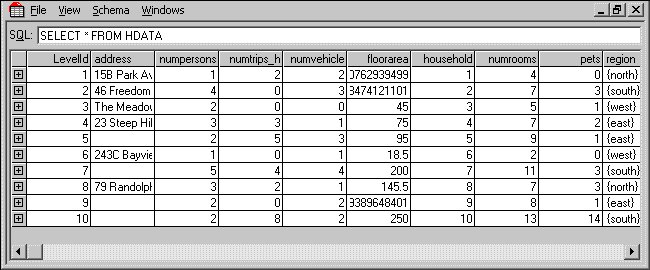
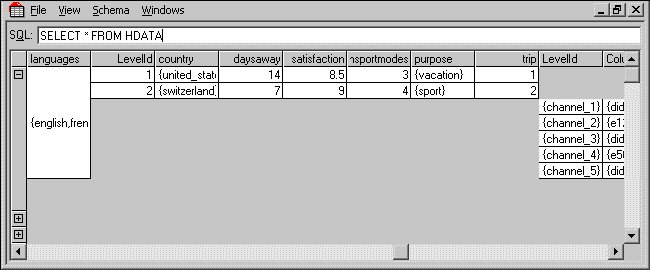
9 Run a query on the hierarchical HDATA tables by entering the following query into the text box and pressing Enter:
SELECT * FROM HDATA
Select Collapse all rows from the View menu to collapse all of the rows. It is now easy to see the number of top-level cases or records in the data set. In the Household sample the top-level cases correspond to households.
The Household sample has a very small number of cases at each level. This is to make it easy to understand what happens when you aggregate the data at the different levels.
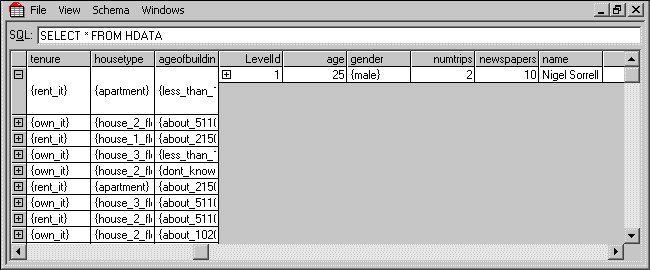
10 Click the + symbol in the first column of the first row to expand the data for the first household. If you scroll to the right, you will come to the first lower-level table (person).
The first household has one person-level case.
11 Click the + symbol in the first column of the person table to expand the data. If you scroll to the right again, you will come to the nested trip and tvdays tables, and then the parallel vehicle table, and its nested rating table.
You have now seen that the hierarchical tables can be nested and the number of rows in the lower-level tables corresponds to the number of times the corresponding loop was iterated for that respondent.
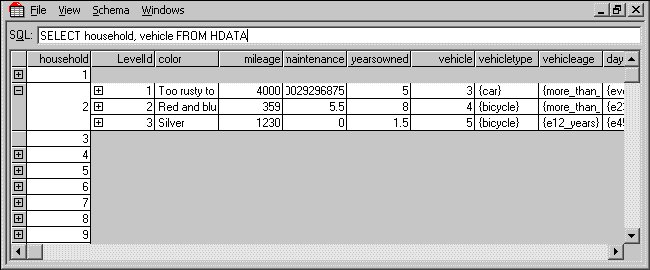
You can run queries on the HDATA tables just as you saw above. For example, the following query returns the household serial number and all of the vehicle-level variables:
SELECT household, vehicle FROM HDATA
Here are the results:
When selecting individual variables that exist in a lower-level table from HDATA, you need to use a sub-select statement. For example:
SELECT household, person.(age, gender, Trip.(DaysAway)) FROM HDATA
See also