How a vertical merge works
In a vertical merge, the case data in each input data source is written in its entirety to the output data. The case data for the first data source is written first, followed by the case data for the second and any subsequent input data sources.
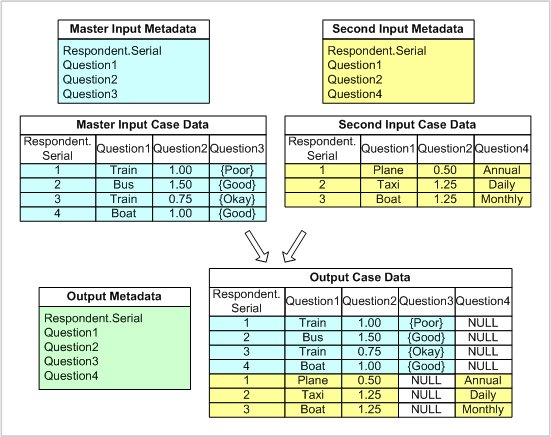
The following diagram shows a vertical merge of two simple input data sources. The first data source is known as the master data source:
The merge has resulted in the merging of the input metadata documents. Therefore, the output metadata and the output case data contain all of the variable names from both input metadata documents. Nulls have been inserted into the output case data for those variables that did not exist in the input data source.
The output case data contains duplicate values for the system variable,
Respondent.Serial. This may cause a problem when using output data sources, such as the Relational MR Database DSC, that do not allow duplicate serial numbers. For ways in which you can avoid this problem, see
Running a vertical merge.
See also