Merging case data
Merging is the process by which the case data from two or more data sources are combined into a single data source. Merging is typically used after the case data has been collected and before the analysis stage of the survey takes place. The following situations are examples of when you might want to carry out a merge:
▪Your organization has carried out a survey from several different offices, and each office has collected the case data in separate data sources.
▪Your organization has carried out a panel survey and collected the case data for each wave in separate data sources.
▪You have been asked to combine supplementary data with your case data.
▪You have extracted all of the open-ended responses from your case data for coding, and you now want to combine the coded responses with your original case data.
The different types of merge
You can use Data Management Scripting to run two different types of case data merge:
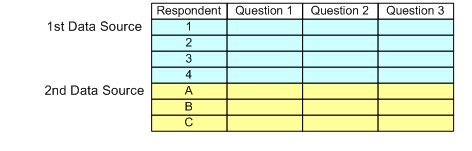
▪In a vertical merge, the cases from the second and subsequent data sources are added after the cases from the first data source. You would typically use a vertical merge to combine case data sources that have mostly the same variables but contain data for different respondents.
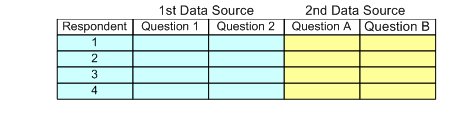
▪In a horizontal merge, the variables from all of the case data sources are combined into a single case. You would typically use a horizontal merge to combine case data sources that have different variables but contain data for mostly the same respondents.
In this section
This section includes topics that describe how the two different types of merge work and how you can run a merge using a data management (DMS) script.
Examples of merging case data, which includes examples of merging Japanese (multibyte) data sources.
See also