How merge deals with metadata conflicts
When a merge is run, conflicts can occur when two or more input data sources contain a variable with the same name but a different data type, or a different set of categories, or some other difference in the metadata for the variable. This topic explains how merge deals with those types of conflicts.
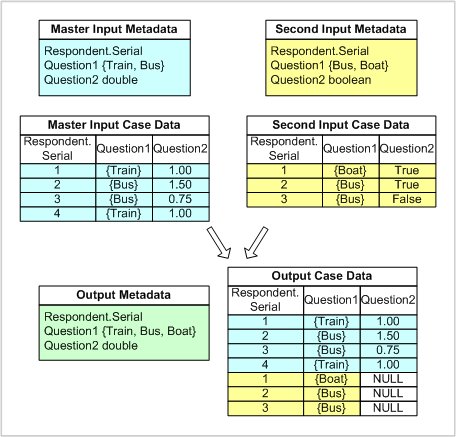
The following diagram shows a vertical merge of two simple input data sources with identical variable names. However, there are differences in the category lists for Question1, and that the data type for Question2 is also different.
When variables have the same name but different data types, the data type defined in the source that is higher in the order of the data sources takes precedence. In the output case data, the variable will then be set to null for all cases from subsequent input data sources that have a different data type. Therefore, in the above example, Question2 has been set to null for all cases from the second input data source. Conflicts of this type are not reported when a data management (DMS) script is run in UNICOM Intelligence Professional.
Because the output metadata is the result of merging all input metadata documents, the output metadata for a categorical variable will include all of the categories from input data sources that have a categorical variable of the same name. Therefore, in the above example, the output metadata for Question2 includes all of the categories from both input data sources.
Variables with different range expressions
If two or more variables have the same name and data type but different ranges, the ranges are merged in the output metadata. For example, if the input ranges are [1..10] and [1..20], they are merged into [1..20] in the output metadata.
If the ranges do not overlap, for example [1..1] and [3..4], the output range is [1..1, 3..4]. When values are validated during an interview or a data management script, the range is used for validation; in this example, 2 is an invalid value.
See also