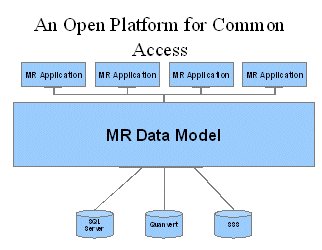
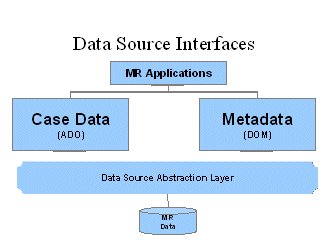
An open UNICOM Intelligence Data Model for the MR Industry... the challenge and the promise
by Peter Andrews
Introduction
Historically, the survey research industry and its computer software suppliers have been forced to accept barriers to the interchange of survey data between software systems and operating environments. These barriers, arising in part from disparate formats for handling the unique requirements of survey data, have been handled primarily through import and export programs, usually of limited effectiveness, and substantial production delays and costs are often incurred as a result. In addition, a core set of common functionality is often created in parallel by each software supplier or division, which affects software costs and ability to adapt quickly to change.
The fundamental need is not only for a medium of interchange for study information and respondent data, but for a means of simplifying the creation and linking together of application programs across a diverse range of functionality.
While significant headway has been made against the basic interchange problem by standards groups such as the Triple-S Committee, the challenge is in the meantime evolving. The survey research industry is beginning to see growing client demand for ever more complex analysis and data mining, for customer relationship management, for web-based publishing of interactive databases, and for executive information systems and marketing information portals that integrate multiple data streams. As we rise to meet these needs, we encounter fundamental inefficiencies arising from the difficulty of integrating applications from multiple vendors to create comprehensive solutions for clients.
The challenges include both logistical and industry issues: on the one hand, the need to handle the requirements of survey data, as well as practical issues that include hierarchical data structures and the tracking of changes over time in longitudinal survey instruments; and, on the other, to achieve consensus among industry players and software providers on the benefits to all of adopting a lingua franca that will allow applications from competing suppliers to share information simply and openly.
This paper will provide an overview of an effort by UNICOM Intelligence to create an open UNICOM Intelligence Data Model that provides an interchange medium, a published Application Programming Interface (API), and extensive functionality to simplify the development and integration of applications for survey research. The paper will review some of the challenges; the potential benefits for agencies and their clients, systems suppliers, and the industry as a whole; and learnings gathered to date from this extensive undertaking.
Design goals and benefits
With these challenges at hand, and with a perceived industry need for a shared, open solution to alleviate the frustrations described above--and to facilitate the creation of larger, more complex next-generation applications--the need seemed clear for a technical solution that would meet at least the following design goals:
▪To develop market research (MR) applications independent of data storage formats
▪To make it easy to read and write MR data and metadata
▪To make it easy to develop new MR applications faster
▪To make it easy to integrate UNICOM Systems, Inc. products end-to-end
▪To make it easy to leverage or integrate third party tools
To do this, the UNICOM Intelligence Data Model must be more than just a repository for survey data. It must provide functionality to allow applications to handle unique aspects of MR data, including multiple response questions, hierarchical data sets, and tracking of study versions, simply and quickly, so that these wheels need not be reinvented for each study. And it must provide an API that simplifies application programming.
The key benefit for the survey research community would lie beyond simple interchange of data, in customization of systems, products and business processes:
▪The opportunity to re-engineer and broaden the business
▪The control to customize the research process
▪The independence to differentiate through innovation
▪The power (speed, quality, and efficiency) to reap quantum productivity gains
An early, simple real-world example might help to illustrate this last point. The construction of paper questionnaires for scanning often involves some fairly extensive formatting, as well as a time-consuming step in which fields on the paper are mapped into the scanning software. We've combined third-party software from multiple vendors with our Data Model and a proprietary application to create a solution that automates much of the formatting--and reduces the mapping process from one that often requires a day or more, depending on the questionnaire, to a matter of seconds. Further, changes to the questionnaire are automatically handled, both in the formatting and in the mapping to the scanning software. This saves multiple iterations of the manual mapping process, and allows agencies to be far more flexible and responsive.
A research agency, using these standard tools, could do the same thing.
Challenges
In addressing this ambitious agenda, the design team faced some key challenges in meeting its design goals while taking into consideration the following:
1 Implementing unique MR case data structures while taking advantage of standard database environments and applications.
2 Fully allowing in metadata for the complexities introduced by factors such as tracking and versioning, global research, and hierarchical data sets.
3 Accommodating the widest possible range of data implementations, including legacy storage formats.
4 Designing simple-to-use API's that would facilitate complex functionality.
5 Choosing industry-standard technologies that would:
▪Facilitate the use of the widest range of new technologies, by us and others.
▪Allow the use of best-of-breed software “building blocks”, so that we and others develop only what's unique to our industry or application.
▪Provide a compatible solution for the widest number of user organizations and industry platforms.
▪Leave us prepared for future technology change.
6 Making the benefits of industry adoption compelling, and the barriers minimal.
7 Overcoming tactical thinking, vs. strategic, both inside and outside UNICOM Systems, Inc.--for example, proprietary and closed vs. open, industry standard, and published.
Meeting the challenge: The UNICOM Intelligence Data Model
Fundamentally, the UNICOM Intelligence Data Model is a set of data/metadata API's to enable applications in a survey research environment to:
▪Author
▪Collect
▪Analyze
▪Display
▪Print
▪Import/export
The UNICOM Intelligence Data Model hides the implementation details of underlying, package-specific storage architectures, so that programmers of application programs need not even be aware of them. Each user program is written using a standard interface. Thus, the application can be insulated from any changes to the underlying data storage format, software environment, and even hardware platform. Further, the UNICOM Intelligence Data Model provides functions to handle common tasks such as simple aggregation and the comparison and manipulation of multiple response data, freeing the programmer to focus on the unique aspects of the application.
The UNICOM Intelligence Data Model API's are based on Microsoft technology, and make it straightforward to create custom applications in the Windows/ASP environment.
Case data
Case (respondent) data is read and written using the standard ADO interface, using a subset of standard SQL commands, extended with a set of functions which provide such features as the ability to access and manipulate multiple response (“multipunch”) category variables. Lower-level OLE DB interfaces are also planned.
Regardless of the underlying data storage format, the ADO provider exposes case data to the consumer application in a very simple virtual relational table. (Additional tables are used when representing hierarchical, or “levels” data.) The columns presented in this “VDATA” table correspond to the variables (for example, questions) requested in the application's SQL query, and the rows correspond to respondent records. The results of a query are presented by the provider as a rowset of the selected data. For example, the following query:
SELECT tested, color, advert, advert_other, product from VDATA
Produces the table shown below:
tested color advert advert_other product
{2} {3} {1} {2}
{3} {2} {1} {2}
{3} {1,3} {1} {1}
{1} {2} {1} {2}
{2} {2} {1} {2}
{3} {3,1} {2} {10}
{1} {4} {7} Poster {10}
In this example:
▪Each row contains response data for a single respondent
▪The tested and product columns contain the data from single response categorical variables, which the Provider presents as integer values.
▪The color column contains the data from a multiple response categorical variable, indicated by the comma-separated values. These values can be presented in order of mention by the respondent.
▪The advert and advert_other columns contain the data from a single response categorical variable, advert. The last row includes an associated open-ended response, and the text for this Other Specify is recorded in the advert_other column.
Metadata
The comprehensive metadata object model is designed to accommodate all required project information other than the case data--that is, information about the study, rather than the respondents, for example:
▪The text of questions that were asked and the names of variables used in analysis.
▪Other source material used in a survey, such as multimedia presentations.
▪Versioning data that allows the reconstruction of all historical versions of a project.
▪Alternative texts for use in different contexts (for example, data collection and analytic environments).
▪Translations of texts into any number of languages.
▪The structure of the data, such as loops, grids, routing, and derived variables
▪Hierarchical data structures
▪Any other details about the case data that you may want to record.
This information is stored in an XML file. The UNICOM Intelligence Data Model interacts with the XML document through another Microsoft standard, the Document Object Model (DOM), and provides a straightforward API for application programs.
In the chart above:
▪Fields can be thought of as mirroring a single RDB field. A single response question might have one field for the categorical response and another for an “all other” verbatim.
▪Each Variable contains the detailed properties for a question or other variable, and can be a container for survey questions or groups of questions, such as grids and rotation groups.
▪Elements are members of response lists.
▪Types are shared response lists, which may be used by multiple questions.
▪Labels hold any other text, and are stored in a multidimensional array according to multiple attributes: user context (for example, question prompts, interviewer instructions), language, and application context (for example, data collection vs. analytic database).
▪Custom Properties are user-defined fields used to extend the metadata content. These can be used, for instance, to hold column locations, tabulation instruction tags--or whatever unique information your authoring tool, questionnaire database, or other application requires.
▪Routings currently hold question order for each version (for example, CATI, Web, WAP) and simple questionnaire logic such as skips and filters. Full, “CATI-style” questionnaire logic is planned for future implementation.
Information on questionnaire versions is also maintained by the Metadata Model. Once a version number is specified by the end-user application, the current view shown to the application will be of that version alone. This permits applications that must be aware of changes to questionnaires over time, such as tabulation databases and OLAP environments, to access exactly what was asked in each wave, for instance, of a tracking study. A synchronization process, initiated as each version is finalized and “locked in”, allows each version to store new, unique information separately, while incorporating information common to multiple versions by reference.
How easy to use is it, really?
The example below shows the six lines of Visual Basic code required to open a metadata object, query it and print out the names of the question fields. Compare this with, say, the time required to write a program to extract the same information from a Triple-S metadata file--or from a closed architecture such as Quanvert, where it can't be done at all.
' VB snippet to print variable names from an MDM document
Dim Document As New MDMLib.Document
Dim V As MDMLib.VariableInstance
Document.Load "MyMetadata.mdd"
For Each V In Document.Variables
Print V.Name ' print names of VariableInstances
Next
Handling diverse data formats
The abstraction layer, which makes diverse data and metadata storage formats accessible through the UNICOM Intelligence Data Model API's in real time, at the individual transaction-level, is achieved through the creation of data source components, or DSCs. These are programs (COM objects), individually written for each storage format, which serve as adapters or translators. Where the high level of integration provided by data source components may not be required--where batch conversions are sufficient, for instance--simpler programs using the API can be written to import studies from proprietary formats into the UNICOM Intelligence Data Model, and thus to the many data formats supported by the UNICOM Intelligence Data Model.
Within the UNICOM Systems, Inc. product line, DSCs have been or will be made available for Quanvert data, IBM SPSS Statistics .sav files, UNICOM Intelligence Interviewer Server's relational database, and so on. A software developer's library is being made available to assist other software suppliers, research agencies with proprietary databases, and others in creating these components and with using the API. Once a DSC is complete, the agency or supplier will have the opportunity, over time, to integrate proprietary applications at the transaction level with the full line of UNICOM Systems, Inc. products and with those of other suppliers who have written DSCs--and import and export programs for these packages should be a thing of the past.
Open architecture
The UNICOM Intelligence Data Model is “open” on two levels: first, it is built around open, industry-standard technologies; and second, it provides an open, published interface (API) for the use of one and all. The first allows DM-enabled programs to interact smoothly with a large body of other standards-based software, allowing them to be combined easily as components of more complex systems. The second allows others outside UNICOM Systems, Inc.--clients, partner companies and even competitors--to easily take advantage of the benefits offered by the UNICOM Intelligence Data Model.
Component technology
The UNICOM Intelligence Data Model is built around industry-standard, open software technologies. From a practical standpoint, the UNICOM Intelligence Data Model's functionality is provided by a set of COM components, implemented as dynamically linked libraries (DLL's). COM is Microsoft's Component Object Model, which allows programs to expose a program interface to other programs. This enables Windows applications to open and control sessions in other programs such as Excel, Word, and PowerPoint. Many survey research agencies use this functionality in Microsoft Office to automate tasks such as report and graphics production. The COM standard facilitates the combining of “component” programs such as the UNICOM Intelligence Data Model, the Office products and many others to build applications.
Your proprietary applications can control the entire process in a straightforward way, using Visual Basic or any of the languages that work with these standards. Thus, our products and others can be combined and extended to create your own proprietary applications--you can add your own unique value, and your own look and feel, combining and adding onto these building blocks. You need not go to the expense and trouble of recreating core functionality--your investment can be focused on those specific areas where your products break new ground.
The use of open standards provides a tremendous efficiency benefit at every level--whether you're simply loading a data set into Excel with a few lines of VBA, or you're creating a complex tracking environment or a marketing information portal. Moreover, because you can work with survey data independently of the underlying storage format, you are not tied to any one product or software supplier. The result is greater flexibility and improved business processes.
Publication
In order to encourage adoption of the UNICOM Intelligence Data Model, the API's are being published and a developer's kit is being made available to the industry. The data of this conference happens to coincide exactly with the public release of the UNICOM Intelligence Developer Documentation Library. Only if the UNICOM Intelligence Data Model--or something like it--is adopted broadly, however, will it yield all of its potential benefits.
To this end, UNICOM Systems, Inc. is supporting industry standards efforts wherever possible. In the MR area, our director of development has been working with the Triple-S committee, and will contribute in any practical way to the converging of our UNICOM Intelligence Data Model with this published standard.
On another front, the Object Management Group (OMG) has published the Common Warehouse Metamodel (CWM), a specification for metadata interchange among data warehousing, business intelligence, knowledge management and portal technologies.
This is a comprehensive standard. It includes relational database structures, OLAP storage, XML structures, data transformation specifications, application of analytic techniques, specification of presentation formats for information, and operational parameters and metrics for data warehouse operation (see
Note below). UNICOM Systems, Inc. has business intelligence products in areas such as analytical CRM, business metrics, and data mining, which currently utilize proprietary, XML-based metadata formats. UNICOM Systems, Inc. is currently working on implementation of a metadata repository that supports CWM-based XMI interchange, which would bridge existing internal standards. While much existing metadata maps fairly easily to the CWM standard, there are places where the standard's definition of variables would have to be extended to support required functionality in the UNICOM Systems, Inc. products. The tentative plan is to adopt this CWM-based repository when it becomes available. If this does in fact happen, then the MR division intends either to adopt the same metadata model or to link with it transparently.
Conclusion: strategic thinking
Our goal at UNICOM Systems, Inc. is to build on the deep, long-term partnerships we have with our clients. We must earn and sustain their trust--they must know that we as a company are out to help them deliver the most effective possible solutions for their customers. UNICOM Systems, Inc. has a clear-cut commitment to open standards and systems, so as to allow clients maximum flexibility to extend and combine our products to create differentiated solutions that add value in turn for their customers. More and more, UNICOM Systems, Inc. products are offered both as turnkey solutions and as components, developers' tools that support our clients in this endeavor.
This isn't the traditional thinking in this industry. Companies have felt that protecting their secrets meant protecting their client bases. The problems that result have become painfully clear to UNICOM Systems, Inc. as, following our acquisition of three MR software companies, we’ve had to rationalize, integrate and maintain within our own product line three parallel lines of traditional MR software that didn't really talk with one another, and somehow to integrate them with our wide array of analytic, business intelligence, graphics, and other applications. One of these companies, Quantime, was well known for closed, proprietary systems such as Quanvert.
Today, though, it is important to leave this kind of tactical thinking behind. As the MR industry changes, as it faces threats from consultancies and from the do-it-yourselfers, as demand emerges for more and more sophisticated data warehousing, analytic, and marketing information applications, the stakes are far too high. Our clients will be--and should be--intolerant of company policy that “traps” them within a product line.
It is important to all of us, as an industry, to think strategically about open systems and to support industry standards. By adopting standard technologies, by publishing our API's, and by working with industry standards organizations, we can as an industry help our clients to compete effectively in this changing marketplace. And when our clients win, we win.
Everyone wins...
UNICOM Intelligence | Competitor | Research Agency |
|---|
Smooth, end-to-end integration of UNICOM Systems, Inc. products. | Reduced costs for import/export features | Best of breed solutions |
Open standards benefit our clients | Interoperability with multiple third party products through a single data model | Efficient development of new applications |
Fewer barriers to adoption of our high-end tools | More credible multivendor solutions | Customization |
Happier clients | Real-time native solutions | Efficiency gains |
| Better integrated solutions | More options |
| Happier clients | Relief for “all eggs in one basket” concerns |
| | Happier clients |
Note The CWM was developed by a group of companies that included IBM, Oracle, and Hyperion. This standard may be merged with another standard from the Meta Data Group, until recently a separate coalition that included Informatica, Microsoft, and SAS. If and when the work of merging these standards is complete, the resulting specification will be issued by the OMG as the next version of the CWM. A single standard should allow users to exchange metadata between different products from different vendors with relative freedom.
About the author
Peter Andrews is Director of Business Strategy in the UNICOM Intelligence Team. A key component of his role is to promote the wide acceptance and use of the UNICOM Intelligence Data Model by customers, future customers, and partners.
Peter has worked in the MR industry for 20 years. He joined IBM Corp. from Audits & Surveys Worldwide (part of the United Information Group), where he was Senior Vice President in charge of New Product Development and, previously, worldwide CIO.
See also