Architecture and key components of Universal Cache
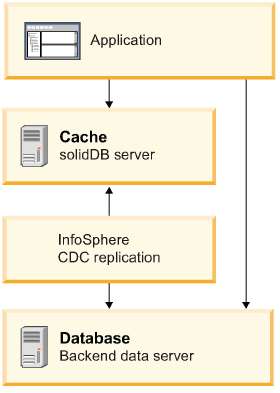
The architecture of the Universal Cache capability is based on three main components: the solidDB® (in-memory) database (cache), a relational database server (backend), and the IBM Infosphere CDC data synchronization software that copies data to and from the cache and the backend.
solidDB® cache database
The solidDB® server implements the cache database (or frontend) in the Universal Cache solution. The cache database benefits from various solidDB® features, such as HotStandby that provides high availability and failover, or shared memory access (SMA) that enables collocating of data with the application.
Backend database
The backend database is a relational, disk-based data server that contains the data to be cached. In many Universal Cache deployment scenarios, you would have an existing database that you can simply replace with a cache database that sits between the backend database and application, making the database appear faster from an application perspective. Only minimal changes would be needed in the database interface layer.
IBM Infosphere CDC replication components
The IBM InfoSphere Change Data Capture replication software ensures that as changes are made to the cache database, the backend database is updated, and vice versa. The IBM Infosphere CDC replication software consists of the following components:
Replication engines
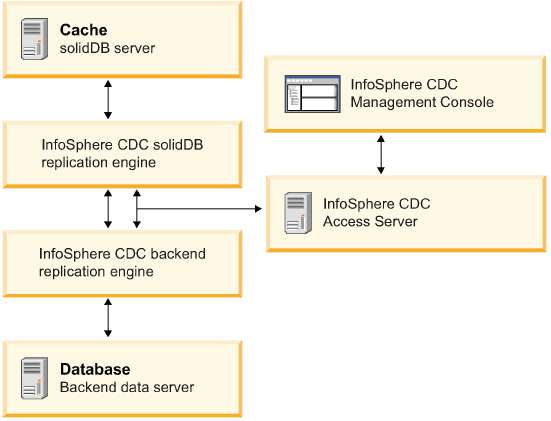
IBM Infosphere CDC replication engines are components that use log-scraping technologies, triggers, or both to capture changes between the two databases. The IBM Infosphere CDC replication engine for solidDB® accesses the solidDB® transaction log to capture data changes and transmits these changes to the backend replication engine, which copies the changes to the backend database.
Similarly, the IBM Infosphere CDC replication engine for the backend accesses the log (or uses triggers) to capture data changes in the backend and transmits these changes to the solidDB® replication engine, which copies the changes to the backend database.
The replication engines run typically on the same hosts as the data servers.
Access Server
The IBM Infosphere CDC Access Server is a process that manages a Universal Cache deployment. It is typically executed as a daemon. The Universal Cache tooling communicate with the Access Server to allow deployments to be configured. Access Server also controls access to the replication environment; only users who have been granted the relevant rights can modify configurations.
Management Console
The IBM Infosphere CDC Management Console is an interactive GUI tool that you can use to configure and monitor replication (caching) subscriptions between the cache and backend databases.
SQL passthrough
The SQL passthrough functionality makes it possible to route SQL operations to the backend database, enabling applications to access data in both databases with a single interface.
For example, the Universal Cache system might be set up so that the frequently accessed data in table T1 is cached to the solidDB® in-memory database. The application can read and modify data in T1 - any changes are replicated to the backend database using IBM Infosphere CDC replication.