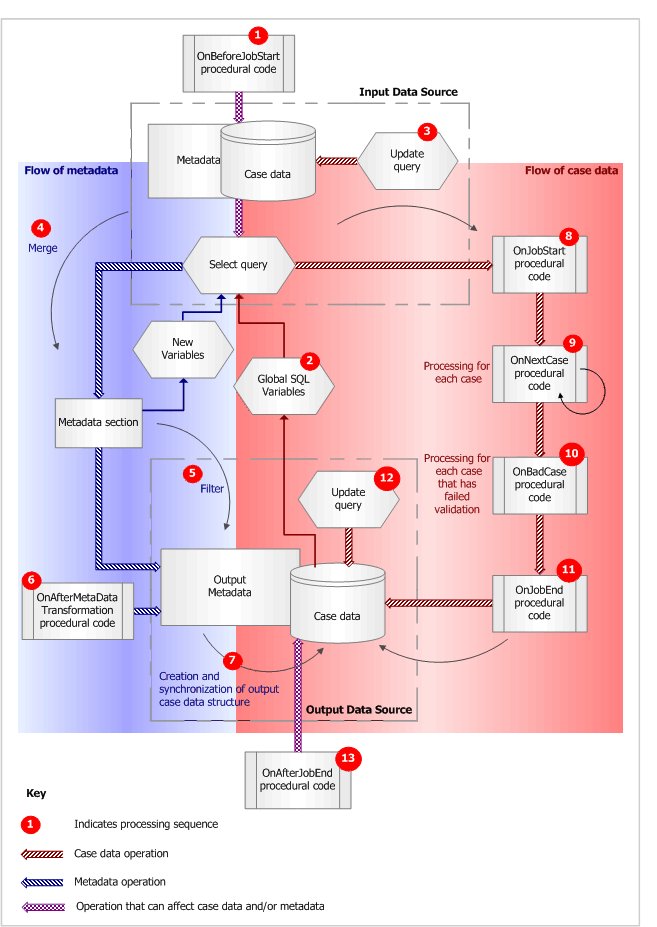
DMS file flow
The following diagram illustrates what happens when you run a standard DMS file. The diagram shows the sequence in which the various parts of the file are executed. However, some parts of the file are optional. For example, the input and output data source update queries are optional as are the GlobalSQLVariables section and the OnBeforeJobStart, OnAfterMetaDataTransformation, OnJobStart, OnNextCase, OnBadCase, OnJobEnd, and OnAfterJobEnd Event sections.
For a diagram that illustrates the processing of a hypothetical job in the form of a timeline, see
Example timeline.
1 The OnBeforeJobStart Event section is processed first. This is typically used to set up card and column allocations in the input data source’s metadata in a job that exports case data to a Quantum .
dat file. See also
Objects in the OnBeforeJobStart Event section.
2 The GlobalSQLVariables section can optionally be used to exchange information between the output and input data source. This is useful when you are transferring case data in batches and want to transfer only records that have been collected since the last batch was transferred. See also
GlobalSQLVariables section.
3 The Update query defined in the
InputDataSource section can be used to add, update, or delete case data in the input data source and is typically used to remove unwanted test data. However, this should be used with caution because the input data source is changed irreversibly.
4 The metadata specified in the connection string in the InputDataSource section is merged with the metadata defined in the Metadata section (see
Metadata section, if there is one. The merged metadata is then made available to the input data source so that any new variables (from the Metadata section) that have been included in the Select Query statement will be returned by the query.
5 The merged metadata is then filtered according to the filter defined in the Select Query in the InputDataSource section and written to the output metadata file defined in the
OutputDataSource section.
6 The OnAfterMetaDataTransformation Event section is run after the metadata merge is complete and is typically used to set up card, column, and punch definitions in the new variables created in the Metadata section. See
OnAfterMetaDataTransformation Event section.
7 The output case data source is created (if it does not already exist) and synchronized with the output metadata.
8 The OnJobStart Event section is run before the processing of the individual cases and is typically used to set up global variables that are required in the OnNextCase and OnBadCase sections. See
OnJobStart Event section.
9 The OnNextCase Event section is processed for each
case included in the transfer and is typically used to clean the case data. See
OnNextCase Event section.
10 The OnBadCase Event section is processed for each case that has failed validation and will not be transferred to the output data source, and is typically used to create a report of bad cases. See
OnBadCase Event section.
11 The OnJobEnd Event section is run after the processing of the last case has been completed and is typically used to close report files and set up weighting using the Weight component. See
OnJobEnd Event section.
12 The Update Query defined in the OutputDataSource section can be used to add, update, or delete case data in the output data source.
13 The OnAfterJobEnd Event section is processed after all other processing has finished. This is typically used to set up tables or to email a report or notification. See
OnAfterJobEnd Event section.
See also