How a horizontal merge works
A horizontal merge combines the variables from cases in two or more input data sources into a single case, which is then written to the output data. Cases are combined (or “joined”) only when they have the same value in their key fields. You define the key field for each input data source in the data management (DMS) script that will be used to run the merge.
The default type of horizontal merge, known as a “full” horizontal merge, will also write to the output data any cases that have not been joined. This ensures that all cases on all input data sources are written to the output data. Data management scripting also supports other types of horizontal merge, but these are typically used less often as they may result in some cases not being written to the output data. The different types of horizontal merge are described later in
Running a horizontal merge.
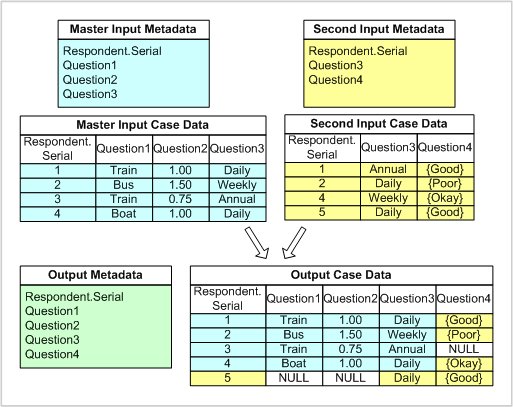
The following diagram shows a full horizontal merge of two simple input data sources that are being joined using the system variable, Respondent.Serial. The first data source is known as the master data source:
The above example illustrates several features of a horizontal merge:
▪The merge has resulted in the merging of the input metadata documents. Therefore, the output metadata and the output case data contain all of the variable names from both input metadata documents.
▪Because cases exist for respondents 1, 2, and 4 on both input data sources, the data for each of those respondents have been combined in the output data.
▪When case data are combined from data sources that have identical variable names, the data from the source that is higher in the order of the data sources takes precedence. This applies even when the value of the data taking precedence is a null or an empty categorical value. In the above example, Question3 exists on both input data sources. So for respondents 1, 2, and 4, the value of Question3 from the master data source is written to the output data.
▪As a result of the previous rule, case data for Question3 in the second input data source has been dropped—in other words, that data has not been written to the output data for respondents 1, 2, and 4. For this reason, horizontal merges are typically used to merge only data sources that contain different variable names.
The cases for respondents 3 and 5 have also been written to the output data. This is a feature of a full horizontal merge; other types of horizontal merges would have dropped one or both of those cases. For those two cases, nulls have been inserted in the output case data for those variables that did not exist in the input data source.
See also