HDATA merge
When the horizontal merge is conducted through the HDATA view (for example, when the SelectQuery in the input data source is specified as select ... from HData), the data for loops that have the same name in different input data sources is processed similarly to variables in the top level. An exception is when the loop key variable is LevelID.
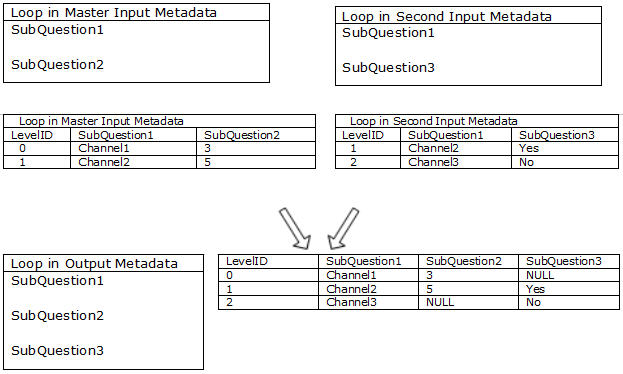
The following diagram shows a full horizontal merge of loop variables in two input data sources:
The diagram illustrates several horizontal merge rules:
▪The merge is the result or merging loops in the input metadata documents. The loops in output metadata and the output case data contain all of the variable names from both loops in the input metadata documents.
▪Because cases exist for LevelID 0 and 1 on both loops in the input data sources, the data for each LevelID is combined in the output data.
▪When case data is combined from data sources that have identical sub variables names, the data from the source that has a higher order takes precedence. This applies even when the value of the data that takes precedence is a null or an empty categorical value. The diagram shows that SubQuestion1 exists on both input data sources loops. The SubQuestion1 value, from the master data source, is written to the LevelID 0 and 1 output data cases.
▪As a result of the previous rule, case data for the loop's SubQuestion1 in the second input data source is omitted (data is not written to the output data for LevelID 0 and 1).
Because the diagram illustrates a full horizontal merge, the cases for LevelID 2 are also written to the output data. The merge type varies when HDATA merging a loop. For expanded numeric loops, the results might be different between VDATA merges and HDATA merges when theLevelID data does not exist in all of the input data source loops.
See also