|
Feature
|
UNICOM Intelligence Data File
|
|---|---|
|
Storage type
|
Single file
|
|
Read
|
Yes
|
|
Write/update
|
Yes
|
|
Unbounded loops (levels)
|
Yes
|
|
Native WHERE clause support
|
Yes
Native expression support includes:
▪For any top level variables in HDATA, WHERE clauses can include any of the following variable types and operators:
|
|
Compressed format
|
Yes
|
|
Multiple user read
|
Yes
|
|
Multiple user write
|
Yes
|
|
Type
|
=
|
<>
|
>
|
<
|
>=
|
<=
|
Is NULL
|
Is Not Null
|
|---|---|---|---|---|---|---|---|---|
|
Long
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Text
|
Yes
|
Yes
|
No
|
No
|
No
|
No
|
Yes
|
Yes
|
|
Double
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Boolean
|
Yes
|
Yes
|
No
|
No
|
No
|
No
|
Yes
|
Yes
|
|
Date
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Categorical
|
No
|
No
|
Yes1
|
No
|
No
|
No
|
Yes
|
Yes
|
|
Rows
|
Columns
|
Seconds
|
|---|---|---|
|
200000
|
250
|
6
|
|
100000
|
500
|
16
|
|
50000
|
1000
|
15
|
|
40000
|
1250
|
19
|
|
31250
|
1600
|
21
|
|
25000
|
2000
|
21
|
|
12500
|
4000
|
33
|
|
10000
|
5000
|
38
|
|
6250
|
8000
|
57
|
|
5000
|
10000
|
69
|
Table | SQL |
|---|---|
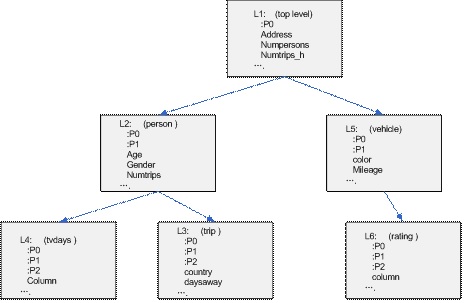
L1 | select [:P0], [LevelId:L], [address:X], [numpersons:L], [numtrips_h:L], [numvehicle:L], [floorarea:D], [household:L], [numrooms:L], [pets:L], [region:S], [tenure:S], [housetype:S], [ageofbuilding:S] from L1 order by [:P0] |
L2 | select [:P1], [:P0], [LevelId:L], [age:L], [gender:S], [numtrips:L], [newspapers:L], [name:X], [person:L], [weight:D], [occupation:S], [languages:S] from L2 order by [:P1], [:P0] |
L3 | select [:P2], [:P1], [:P0], [LevelId:L], [country:S], [daysaway:L], [satisfaction:D], [transportmodes:L], [purpose:S], [trip:L] from L3 order by [:P2], [:P1], [:P0] |
L4 | select [:P2], [:P1], [:P0], [LevelId:S], [Column:S] from L4 order by [:P2], [:P1], [:P0] |
L5 | select [:P1], [:P0], [LevelId:L], [color:X], [mileage:L], [maintenance:D], [yearsowned:D], [vehicle:L], [vehicletype:S], [vehicleage:S], [daysused:S] from L5 order by [:P1], [:P0] |
L6 | select [:P2], [:P1], [:P0], [LevelId:S], [Column:S] from L6 order by [:P2], [:P1], [:P0] |
:P0 | address:X | |
|---|---|---|
1 | 15B Park Avenue, Harrogate, HG1 4TY | ... |
↓2 | 46 Freedom Lane, Brighton, BN2 3YT | |
→3 | The Meadows, Clifton Heights, BS34 3EG | |
4 | 23 Steep Hill, Norfold, CB64 5TY |
:P1 | :P0 | age:L | |
|---|---|---|---|
1 | 1 | 25 | .. |
↓2 | 1 | 45 | .. |
↓2 | 2 | 43 | .. |
↓2 | 3 | 15 | .. |
↓2 | 4 | 12 | .. |
→3 | 1 | 72 | .. |
3 | 2 | 81 | .. |
4 | 1 | 32 | .. |
4 | 2 | 9 | .. |
4 | 3 | 2 | .. |
:P1 | :P0 | age:L | |
|---|---|---|---|
1 | 1 | 25 | .. |
2 | ↓1 | 45 | .. |
2 | →2 | 43 | .. |
2 | 3 | 15 | .. |
2 | 4 | 12 | .. |
3 | 1 | 72 | .. |
3 | 2 | 81 | .. |
4 | 1 | 32 | .. |
4 | 2 | 9 | .. |
4 | 3 | 2 | .. |
:P2 | :P1 | :P0 | Column:S |
|---|---|---|---|
1 | 1 | 1 | 54; |
1 | 1 | 2 | 55; |
1 | 1 | 3 | 54; |
1 | 1 | 4 | 57; |
1 | 1 | 5 | 54; |
2 | 1 | ↓1 | 56; |
2 | 1 | ↓2 | 55; |
2 | 1 | ↓3 | 54; |
2 | 1 | ↓4 | 54; |
2 | 1 | ↓5 | 54; |
2 | 2 | →1 | 58; |
2 | 2 | 2 | 58; |
2 | 2 | 3 | 58; |
MDM variable type | UNICOM Intelligence Data File schema type | Column name suffix |
|---|---|---|
Long | Integer | :L |
Double | Real | :D |
Text | Text | :X |
Date | Real | :T |
Boolean | Integer | :B |
Categorical | Integer or Text | :Cn or :S |
skidemo | UNICOM Intelligence database | UNICOM Intelligence file | Quantum | Quanvert | SPSS |
|---|---|---|---|---|---|
Total size | 19 | 2.18 | 0.9 | 3.25 | 1.7 |
Backup | 18.1 | 0.65 | * | 2 | * |
skidemo | UNICOM Intelligence database | UNICOM Intelligence file | Quantum | Quanvert | SPSS |
1 variable | 0.062 | 0.062 | 0.109 | 0.031 | 0.062 |
5 variables | 0.11 | 0.063 | 0.204 | 0.078 | 0.078 |
All variables | 1.078 | 0.562 | 0.843 | 0.672 | 0.61 |
skidemo | UNICOM Intelligence database | UNICOM Intelligence file | Quantum | Quanvert | SPSS |
All variables | 0.01 | 0.008 | 0.109 | 0.359 | 0.09 |
skidemo | UNICOM Intelligence database | UNICOM Intelligence file | Quantum | Quanvert | SPSS |
|---|---|---|---|---|---|
Records per second | 80 | 1897 | 1523 | * | 1971 |
skidemo | UNICOM Intelligence database | UNICOM Intelligence file | Quantum | Quanvert | SPSS |
|---|---|---|---|---|---|
1 variable | 0.719 | 0.219 | 0.282 | * | 0.578 |